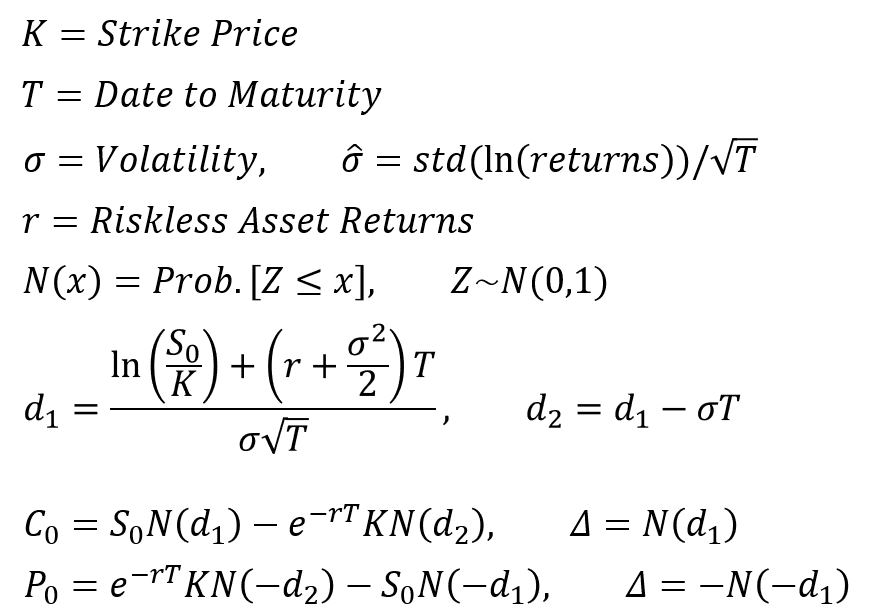Today I would like to present a back test on statistical arbitrage strategy with Cryptocurrency Futures.
Cryptocurrency is an emerging form of financial instrument, renowned as its safeness and decentralization. What's more, many investors build up exchanges to trade these digital assets. Some exchanges, for example, CME Group, OKCoin and BitMEX, even designed Futures Contract against these emerging assets.
These new derivatives are really interesting, not only because of their underlying assets are young and innovative, but also the way these futures are delivered at maturity time.
CME Group, one of the largest exchanges in the U.S. and in the world, for example, provide Bitcoin Futures settled and delivered in cash, which is U.S. Dollar. This instrument is great for hedge funds, because in that way they might be able to avoid the risks in holding the real form of digital assets.
However, for some other individual investors and Cryptocurrency funds, this might not be satisfying because they would like to hold only digital assets and only remit to U.S. Dollar, or any other currency they prefer to, when they deliver earnings to investors or paying out wages to managers.
Therefore, they prefer to Futures that settled and delivered in Cryptocurrency only. OKCoin, hence, offered BTC, ETH and many other Cryptocurrency that transacted via these currencies only. BitMEX, for example, provides only BTC as the only 'cash' in settlement and delivering of swaps, futures and other derivative contracts it provides.
In this article, we focus on the BTC, ETH, EOS, XRP and LTC futures against USDT (a Cryptocurrency that fixes its price against U.S. Dollar) listed in the OKCoin Exchange and see whether these futures have any arbitrage opportunities in the cross-time statistical arbitrage within these futures.
I. Data Source
Because of the idiosyncrasy of statistical arbitrage, we only focus on high-frequency data. We subtracted data from 12:00 to 23:59 in Jul 22, 2018 from OKEx (OKCoin) with its available public websocket API.
We divide the dataset into two parts: one for training model and the other for testing.
II. Principles
First, we select two trading assets from the available trading pairs, for example, BTC Futures this week (FT) against BTC Futures this quarter (FQ). With the data in training set, we build a single-variable linear model, with the slope coefficient as replicating ratio.
Second, we test the stationarity of the residuals in the first simple model. This is greatly important statistically and economically because stationarity suggests that the prices of the two futures are sharing a co-movement in their price. If not, the mean reversion might not eliminate.
For instance, in our dataset, we set y as the mid-price in ap1(the first level of ask price) and bid1 of BTC Futures matured this quarter, and model it against constant and mid-price of the Futures matured this week. The result is that ADF statistics is far less than 1% critical value, suggesting the residual is stationary, which means that it should converge to some constant.
mid_FQ ~ const + mid_FT
ADF Statistic: -4.358316
p-value: 0.000352
Critical Values:
1%: -3.430
5%: -2.862
10%: -2.567
Then, we develop a strategy to replicate the second Futures with the first one via the model we have built in the first step. The cross-time price movements should be linear, as suggested by literature because any violation against the pricing formula F = S*exp(r*T) would indicate arbitrage opportunity.
However, the above formula might not hold in reality because BTC can hardly be shorted, because it has high borrowing interest rate. But Generally we could build a substantially great linear model to replicate the second Futures with only the first Futures across maturity.
Finally, because we are sure that the discrepancy of one Futures asset against its replicated asset would converge to zero, we are aware that such arbitrage opportunity would decrease to zero. Therefore, it should be a great strategy to short the replicating portfolio when its price is relatively high, and long it when its price is somewhat lower.
III. Empirical Analysis
For example, suppose that y is BTC FQ(Futures matured this quarter) and x is BTC FT(Futures matured this week), and we have the model: y = a + b*x + e statistically.
Then, we compute the 5% and 95% percentile of the residual e: it suggests the deviation of a + b*x against its real price y. In our data sample, 95% percentile of e is about 6USD, and the 5% percentile about -6USD.
Our strategy is simple: short b shares of x and long 1 share of y when a + b*x - y = -e > 0, e < 0, or to be more stable, e less than the 5% percentile; long b shares of x and short 1 share of y when e exceeds the 95% percentile. This strategy should be obvious: short the spread of y - a - b*x when the residual is really large; and long the spread when otherwise.
Suggest that we only invest in 1 USD for the futures, and the performance in the testing period is shown in the following image:

It shows that without transaction cost, we can earn abnormal high profits, but the arbitrage opportunity disappears when taking transaction costs into account.
We have also tested ETH, EOS, XRP and LTC futures. As a result, most figures show the similar results. However, the PnL of XRP Futures statistical arbitrage strategy might be more volatile, as it has positive earnings even when transaction costs are taking into account.
This strategy has some shortcomings: it introduces only data for one day, which might be too small. Besides, it trains and tests with only one split and the testing part might need some more up-to-date formula. Some advanced techniques can also be considered.
In conclusion, the Futures market of Cryptocurrency-to-Cryptocurrency is somehow efficient. Maybe only the most clever and careful investors can be the successful arbitrager in this market.