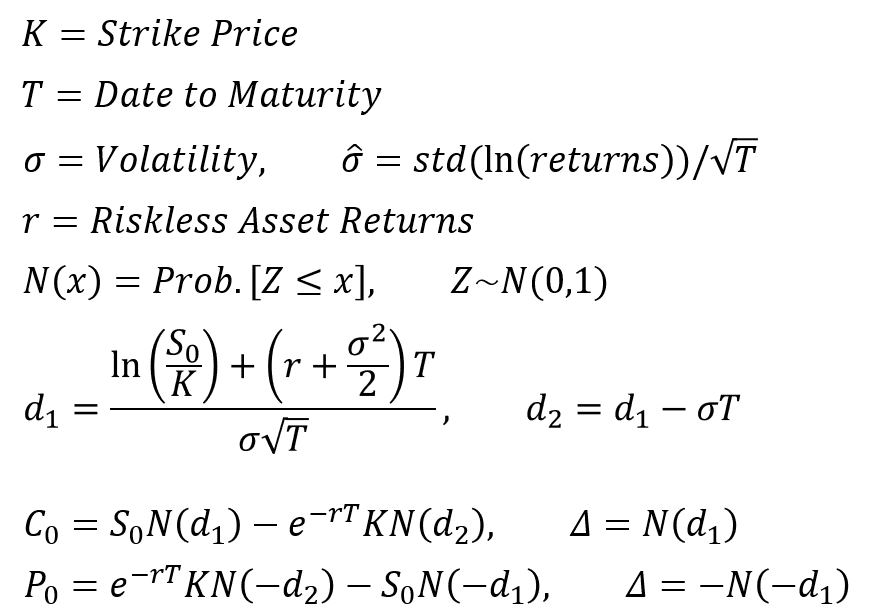I have implemented binomial-tree option pricing model to the only listed financial option in China: option on 50ETF. The results show that though somewhat similar, binomial-tree model cannot successfully price the options, and it might underestimate the risks which could lead to raising the prices.
I. Basic Steps on Binomial-Tree Model
Binomial-Tree Model assumes that in each time period, the stock price would either go up or go down, with a similar scale, as shown in the following graph:
Assuming that we know the exact parameter of the growth and the variance, we can calculate the expected tree of stocks. Specify a certain dt up to its exercise date, we may get a stock tree.
After building the stock tree, we can derive the corresponding option tree. However, unlike calculating from the first node, in the Binomial-Tree Model, we calculate the price of the option from the end of the tree. That is, we calculate all the possible prices of option on the exercise date, and backwardly propagating the previous prices by the formula shown above, and leading to the estimated price at present.
We can also calculate the delta by (C(1,1)-C(1,0))/(S(1,1)-S(1,0)) to show the sensitivity of option to its underlying asset.
Similarly, replacing C(N,m) = Max(S(N,m)-K,0) with Max(K-S(N,m),0), we can derive the price at exercise date of the put option, and by remaining other steps the same, we might calculate the P(0,0) and its delta.
The Python codes of binomial tree are shown as following:
import numpy as np
def binomial_tree(r,mu,sig,S0,K,T,N,isCall):
# European Option Pricing
dt = T/N
q=(np.exp(r*dt)-1-mu*dt)/(2*sig*np.sqrt(dt))+0.5;
U=1+mu*dt+sig*np.sqrt(dt)
D=1+mu*dt-sig*np.sqrt(dt)
DCF=np.exp(-r*dt)
S=np.zeros((N+1,N+1))
C=np.zeros((N+1,N+1))
S[0,0]=S0
for j in range(1,N+1):
S[0,j]=S[0,j-1]*D
for i in range(1,j+1):
S[i,j]=S[i-1,j-1]*U
if isCall == True:
for i in range(N+1):
C[i,N]=max(S[i,N]-K,0)
else:
for i in range(N+1):
C[i,N]=max(K-S[i,N],0)
for j in range(N-1,-1,-1):
for i in range(0,j+1):
C[i,j] = DCF*((1-q)*C[i,j+1]+q*C[i+1,j+1])
C0 = C[0,0]
alpha0 = (C[1,1]-C[0,1])/(S[1,1]-S[0,1])
return C0, alpha0
II. Empirical Analysis on 50ETF Option Data
50ETF (Managed by Huaxia Fund) is the only active tradable in-the-market financial asset who has derivative option. Its price basically reflects the future aspiration of overall financial market in China. Because the option on 50ETF is European, the following analysis would only consider European method.
I have collected the data of the basic information and daily price of underlying 50ETF prices (from Wind), and the data of information in the scale of tick of 50ETF option (private dataset). Because the dataset of option is too large, I might not put all of them online. I would only list one sample of the dataset here. Please e-mail me for further request. Other data are available here:
Price of 50ETF,
Basic Information about 50ETF Option,
non-risk asset returns in China,
description of the option dataset,
one sample of the option dataset. The range of test time is from 2015-07-31 to 2015-11-30.
The price of 50ETF is like the price of the stock shown above, and mu is estimated by its historical returns from the estimated date to it was one year ago, dividing the time of each iteration. sigma is estimated by the standard variance with a similar method.
Codes of reading data, determining parameters, and pricing options for each option with respective strike price on each date with trading volumes greater than 0 are as follows:
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import ffn
import datetime
import calendar
import os
# Read Basic Information of the Data
def filterMonth(kwd, files):
return [file for file in files if file.find(str(kwd)) != -1]
df_results = pd.DataFrame(columns=['TradingDate','SYMBOL','BinomialPrice','delta','Close'])
df_etf = pd.read_csv('50ETF.csv')
df_etf.index = pd.to_datetime(df_etf.TradingDate)
df_description = pd.read_excel('SHSOL1_description.xlsx')
df_basicinfo = pd.read_excel('Basic Information.xlsx')
df_basicinfo.index = df_basicinfo['期权代码'] #'期权代码' means the symbol of the option
df_nonrisk = pd.read_csv('nonrisk.csv')
df_nonrisk.index = pd.to_datetime(df_nonrisk.Clsdt)
# Load the price of option
year = 2015
for month in range(7,12):
monthRange = calendar.monthrange(year, month)
startdate = datetime.datetime(year,month,monthRange[0])
enddate = datetime.datetime(year,month,monthRange[1]) #One Month at most at one time
df_etf_inrange = df_etf[startdate:enddate]
ymonth = pd.to_datetime(startdate).year*100+pd.to_datetime(startdate).month
df_description = pd.read_excel('SHSOL1_description.xlsx')
cols = df_description['字段名'].tolist() #'字段名' means the name of the character
for (root, dirs, files) in os.walk('SHSOL1_TAQ1(1-100)'):
files = filterMonth(ymonth, files)
df = pd.DataFrame()
for f in files:
print(f)
if not df.empty:
df = pd.concat( [df,\
pd.read_csv('SHSOL1_TAQ1(1-100)\\'+f,names=cols)], axis=0 )
else:
df = pd.read_csv('SHSOL1_TAQ1(1-100)\\'+f,names=cols)
contracts = df.SYMBOL.unique()
df.index = pd.to_datetime(df.BUSINESSTIME)
# Load Parameters and Pricing
diags = []
for date in pd.date_range(startdate,enddate):
if date.to_pydatetime() in df_etf_inrange.index:
close = df_etf_inrange.Close[date.to_pydatetime()]
S0 = close
tradableOptions = df_basicinfo[(df_basicinfo['上市日'] <= date.to_pydatetime())&(df_basicinfo['到期日'] > date.to_pydatetime())] #'上市日' means the first date in the market; '到期日' means the last date, or strike/exercise date
returns = ffn.to_returns(df_etf.Close[pd.to_datetime(date)-datetime.timedelta(days=365):pd.to_datetime(date)-datetime.timedelta(days=1)])
mu0 = returns.mean()
sig0 = returns.std()
Ts = tradableOptions['到期日'] - date #'到期日' means strike/exercise date
Ks = tradableOptions['行权价'] #'行权价' means strike/exercise price
N = 20
r = df_nonrisk.Nrrdata[date.to_pydatetime()]/100
isCall = tradableOptions['认购/认沽'] == '认购' #'认购' means 'Call'; '认沽' means 'Put'
for option in tradableOptions.index:
if option not in contracts:
continue
reals = df[(df.SYMBOL==option)&(df.VOLUME!=0)]
if reals.empty:
continue
else:
reals = reals.LASTPRICE[date.strftime('%Y-%m-%d')]
if reals.empty:
continue
K = Ks[option]
T = Ts[option].days/365
isC = isCall[option]
real = reals[~np.isnan(reals)][-1]
mu = mu0/(T/N)
sig = sig0/np.sqrt(T/N)
binomial0, alpha0 = binomial_tree(r, mu, sig, S0, K, T, N, isC)
diags.append([date,option,binomial0,alpha0,real])
df_results = pd.concat([df_results,pd.DataFrame(diags,columns=['TradingDate','SYMBOL','BinomialPrice','delta','Close'])])
df_results.to_csv('binomialResults.csv')
The results of the 'TradingDate', 'SYMBOL', 'BinomialPrice', 'delta', and 'Close' are stored in '
binomialResults.csv'. Show the scatter plot of the binomial price and close price, we have:
plt.figure(dpi=200)
plt.title('Binomial Price against Real Price')
plt.xlabel('Binomial Price')
plt.ylabel('Real Price')
plt.xlim(0,0.6); plt.ylim(0,0.6)
plt.plot(df_results.BinomialPrice,df_results.Close,ls=' ',marker='.')
plt.savefig('Binomial Price against Real Price.png')
The plot shows that the price of binomial tree model is somewhat similar with the real price, but it seems that it is slightly smaller than the real price. We try the following codes to show the result of one sample t-test to show how similar the results are:
from scipy import stats
ttest_1sample = stats.ttest_1samp(df_results.BinomialPrice-df_results.Close, 0)
In[1]: ttest_1sample
Out[1]: Ttest_1sampResult(statistic=-22.871123481744913, pvalue=1.430363679347074e-91)
It shows that binomial-tree model significantly underestimate the option price. It seems that the risk in the option market cannot be successfully reflected in this model.